
There’s big news in the data world as Fivetran picks up dbt Labs. Tristan Handy, dbt Labs founder, writes about the merger: “It really all comes down to two principles that both products hold dearly: simplicity and openness.” dbt has indeed done that for data engineering by enabling production-grade data pipelines that rely on open standards.
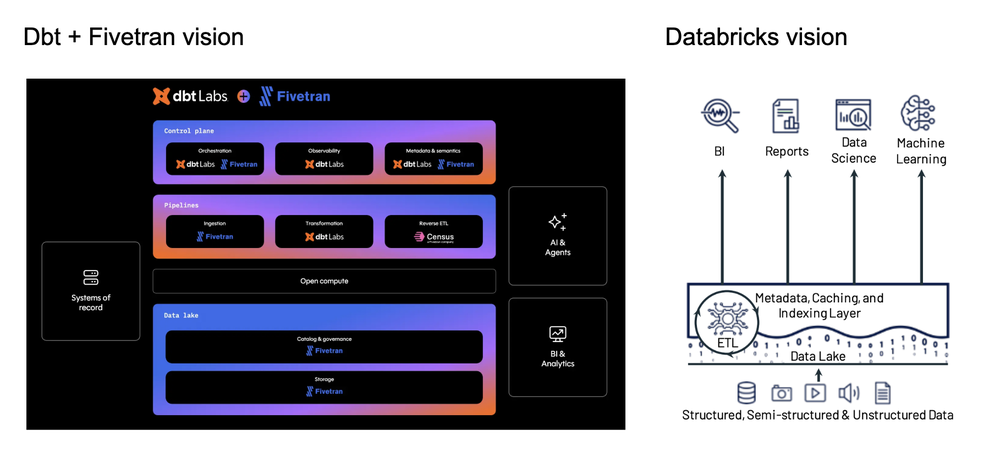
The vision for dbt plus Fivetran looks a lot like the Lakehouse vision put forth by Databricks a few years ago, if you turn the graphic on its side. Storage and governance are separate, with AI, data and analytical workloads that can access what they need when they need it.
The separation of concerns improved the data stack
Over the past decade, the stack modularized. Databases always separated storage, but beyond that it was a mess. Enterprise systems like SAP and Salesforce owned the whole stack, and weren’t terribly friendly about data portability. Business Intelligence products often came in from the other angle. At Tableau, we made huge progress in enabling business users to explore their data, but we made the problem worse. By necessity, Tableau had to work at several layers of the data stack: there simply wasn’t an interoperable semantic layer or governance model to attach to. Similarly, Looker brought semantics into the presentation layer with LookML.
As the data stack evolved, separating concerns solved some huge problems:
- Irreproducible data pipelines → standardized, versioned ETL/transform (e.g., dbt).
- Semantics implicit in various systems → explicit, managed semantics from various vendors
- Data gravity lock-in → decoupled storage & compute, data sharing, open formats
So it’s all great now, right? …right?
It’s much better! Except if you look at the presentation layer of data. Tableau and Looker, both acquired, slowed their innovation. They were also built for a different data stack and era.
You could say the presentation layer has lagged. Maybe it’s even gone backwards.
On the universal communication platform, the web, images of data still rule. Many of these images don’t use established best practices for communicating with data, so they are both badly designed and static. There are some interactive views, but they tend to be quite limited or so slow that the interactivity is not worth using.
Companies that need to share data on the web, like SaaS companies building reporting for their customers, have a hard choice: embed the last generation of BI products, or fund custom front-ends that require time and skills that they can’t spare.
Why can’t the presentation layer be simple and open too?
Unfortunately, the presentation layer today is anything but. There’s still no way to leverage a modular presentation layer that is pluggable, interoperable, and performant.
What’s also notable about the two diagrams above is that they don’t really refer to a presentation layer at all. The application layer is “over there” and not relevant. But is that how it should be? Do we really believe that applying all that valuable data in the data stack should be reliant on proprietary systems and extremely skilled individuals?
We believe the data stack will ultimately look more like this:
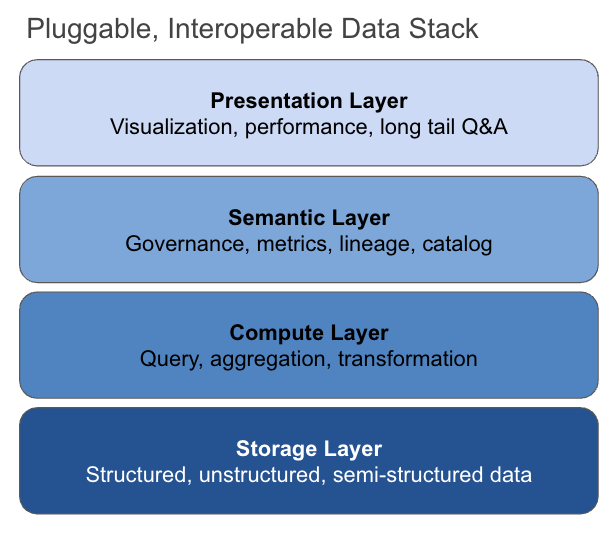
This is possible today because there are new building blocks to work with:
- Open table formats & columnar interchange: Iceberg (table format) and Arrow (language-independent, in-memory transfer) improve portability and performance across engines.
- DuckDB enables analytical SQL in the browser, opening up a potential step change in performance.
- Ecosystem: Databricks, Snowflake and now Fivetran + dbt provide composable platforms that a presentation layer can build on.
- Mosaic builds on DuckDB and WASM to provide an architecture for greater scalability, extensibility, and interoperability of interactive data views on the web.
- AI enables domain understanding, application of best practice, and the ability to handle natural-language questions.
As the stack consolidates around modularity and openness, the presentation layer should do the same. Oh, and it should be fast enough for the web.
I’d love to hear your thoughts on this– email me at ellie@ridgedata.ai or find me on Linkedin.
